Overview of File System Processing
In this tutorial I will show an overview of how to delete files , empty folders, including empty sub-folders by improving system performances
Like my previous 2 posts Real-time FileWatcher System Monitor using TPL DataFlow , Asp.NET Web API, SignalR, ASP.net MVC and Angular JS and Using Spring.NET and Quartz.NET Job Scheduler , I will use asynchronous programming, Task Parallel Library , TPL Dataflow and Quartz.NET Job Scheduler
I will start by showing several ways of exploring file system and at the end of this tutorial, I will talk about performance
Abstract
Our goal is to delete all files using a criteria ( creation between to dates or created n days ago), But we cannot delete a directory if it contains subdirectories or files because this subdirectories or files may contain files that does not match our criteria.
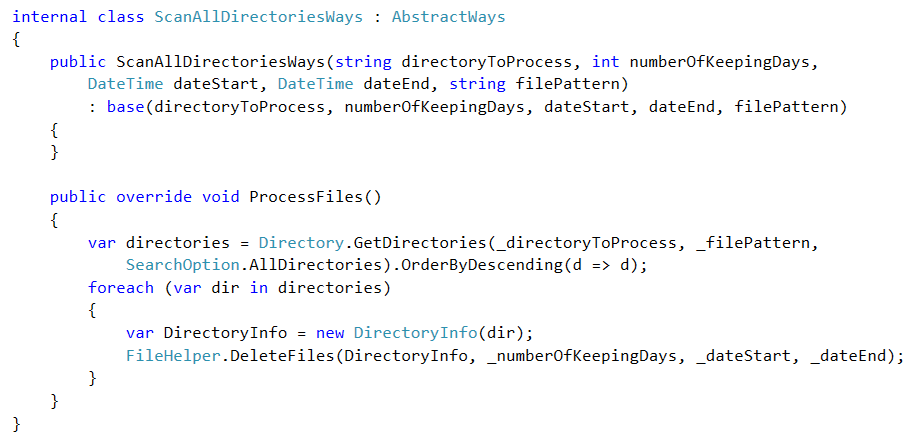
So a better way is to order all directories descending by name
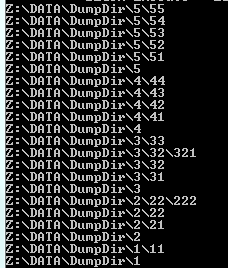
Suppose we have this filesystem

A way to explore our file system, can be as follows
I. GET ALL ORDERED DIRECTORIES AND ITERATE THROUGH EACH OF THEM
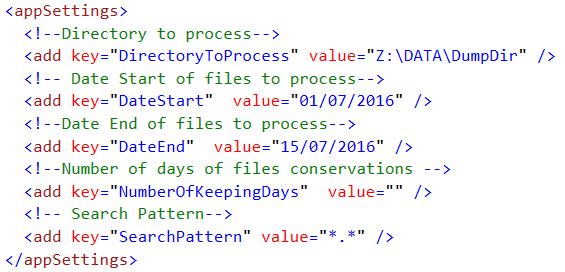
Lets create first some configuration settings :
- DirectoryToProcess is the parent directory
- DateStart is the date start of files to process
- DateEnd is the date end of files to process
- NumberOfKeepingDays is Number of days of files conservations : files created NumberOfKeepingDays days ago must be deleted
- SearchPattern is a criteria to specify witch file or directory must be processed.
our goal is if NumberOfKeepingDays is not provided, we process file between DateStart and DateEnd
Lets create a GetAllDirectoriesWays class
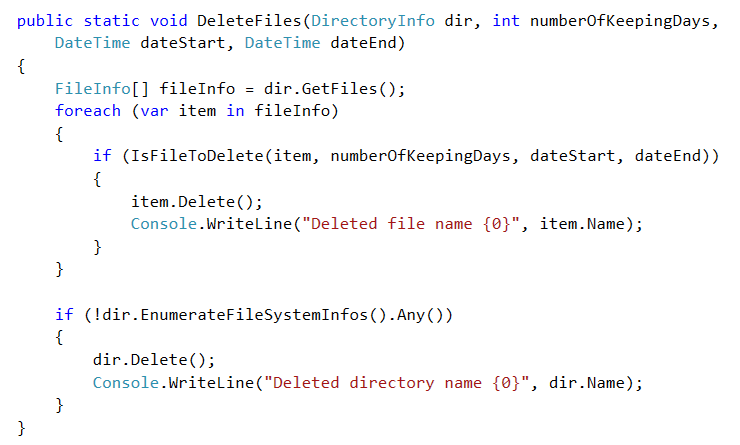
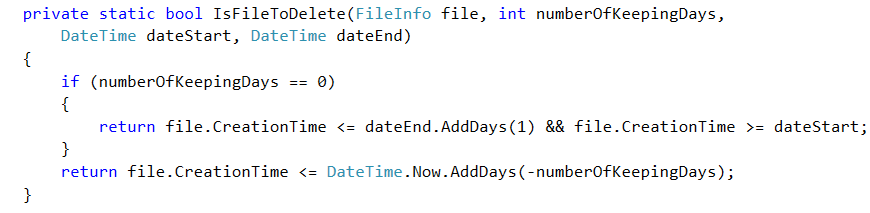
II. ITERATE THROUGH ORDERED DIRECTORIES AND PROCESS ITEM BY ITEM
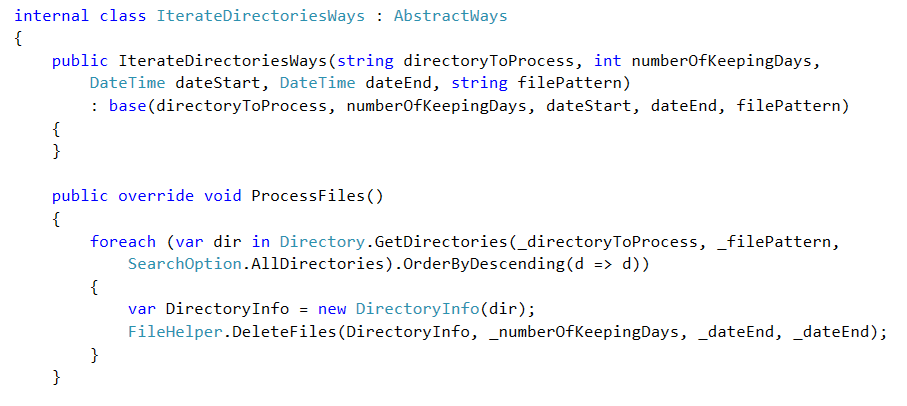
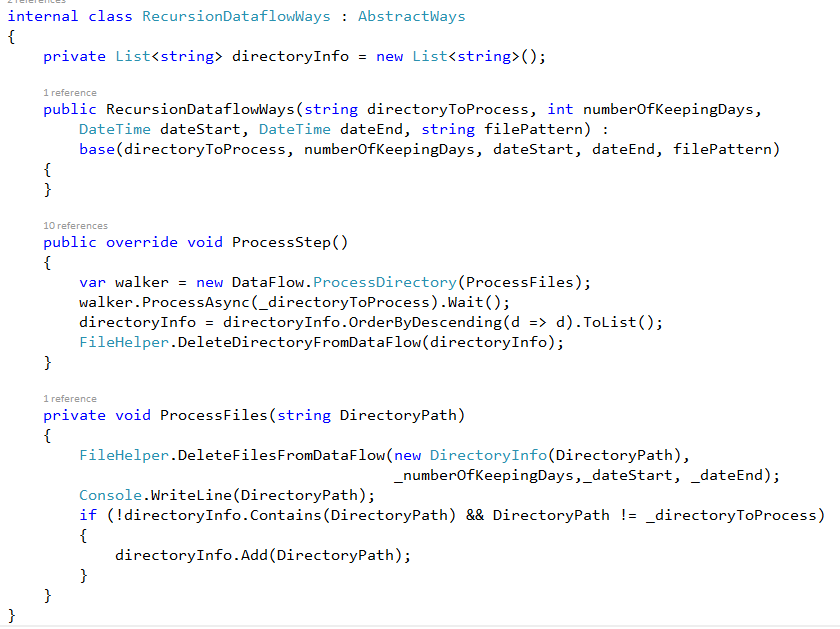
III. HANDLE DIRECTORIES RECURSIVELY

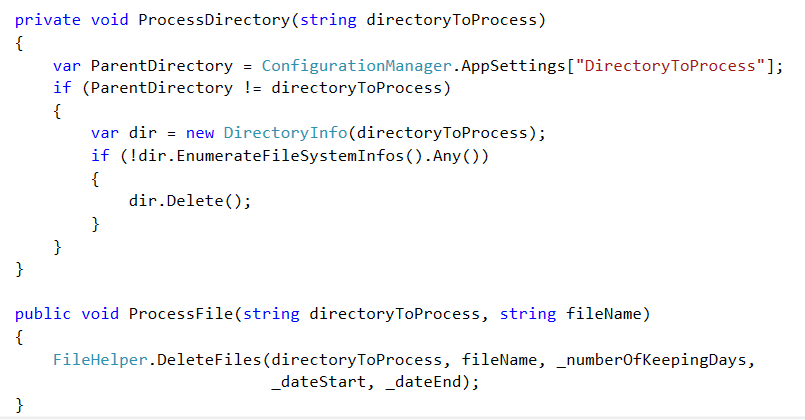
IV. RUN PROCESSSTEP AS A TASK

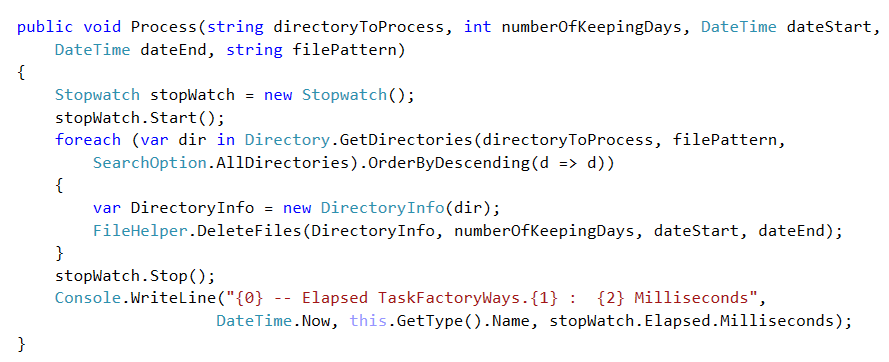
V. RUN PROCESSSTEP AS A TASK WITH CANCELATION TOKEN AND REPORT PROGRESS

VI. RUN PROCESSSTEP BY LOAD BALANCING USING TPL DATAFLOW
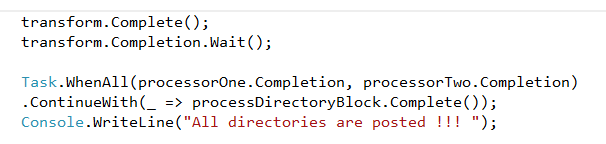
we want to just write the code, and the way we structure it results in no synchronization issues. So we don’t have to think about synchronization. In this world each object has its own private thread of execution, and only ever manipulates its own internal state.
Instead of one single thread executing through many objects by calling object methods, objects send asynchronous messages to each other.
If the object is busy processing a previous message, the message is queued. When the object is no longer busy it then processes the next message.
Fundamentally, if each object only has one thread of execution, then updating its own internal state is perfectly safe.
TPL Dataflow enable us to achieve this goal by building blocks. Blocks are
essentially a message source, target, or both. In addition to receiving and sending messages, a block represents an element of concurrency for processing the messages it receives.
Multiple blocks are linked together to produce networks of blocks. Messages are then posted asynchronously into the network for processing.
Lets first create a class that inherits from AbstractWays
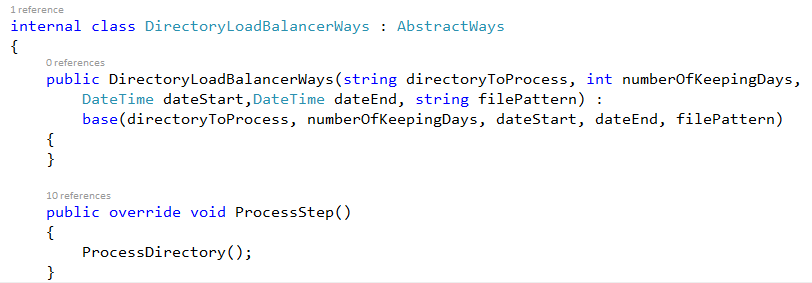
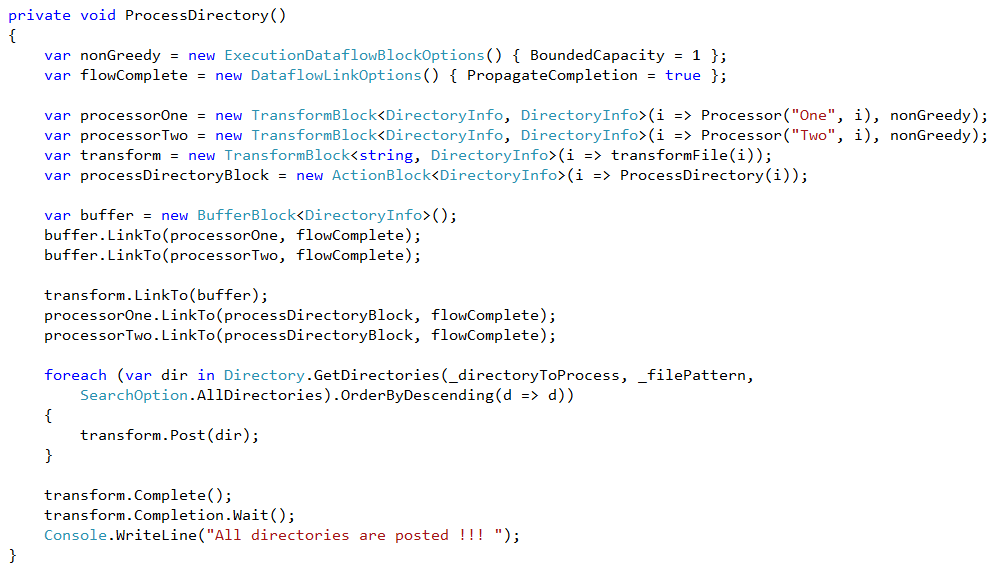
Our system works as follow :
- A transformBlock that tranform directory path to DirectoryInfo and post it as message to a BufferBlock
- BufferBlock is linked to processorOne and processorTwo, so if processorOne is busy, then processorTwo will process message
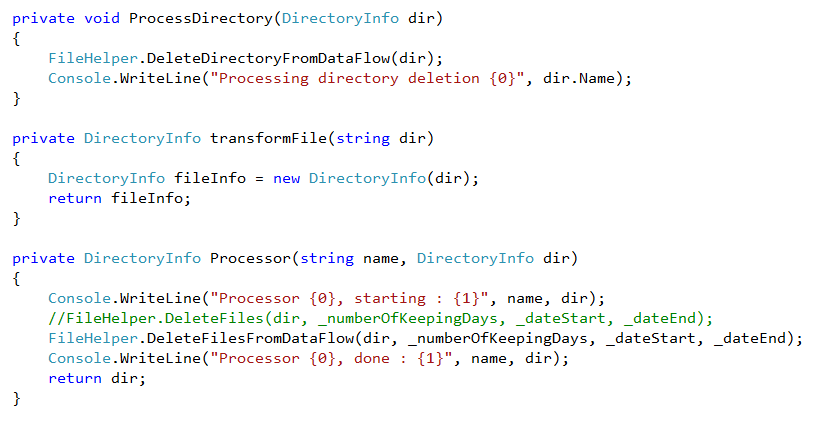
- processorOne and processorTwo are transformBlocks linked to processDirectoryBlock , processDirectoryBlock is a transfromBlock and has the responsability to delete files in current directory using a criteria
Consider the following file system
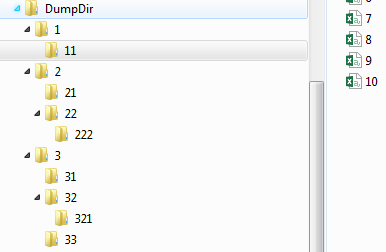
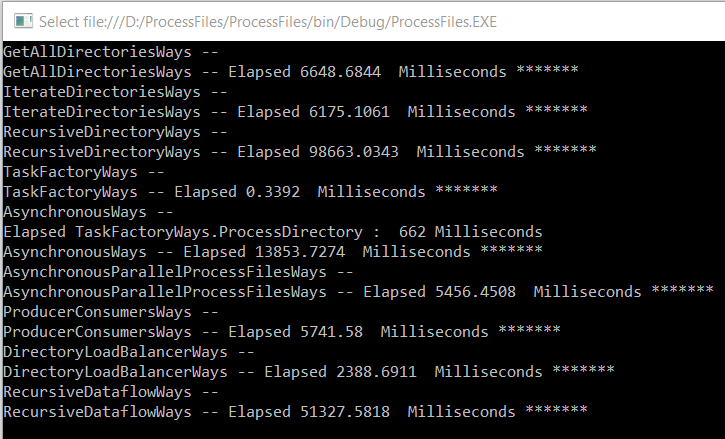
An execution of the previous code may produce the following output result
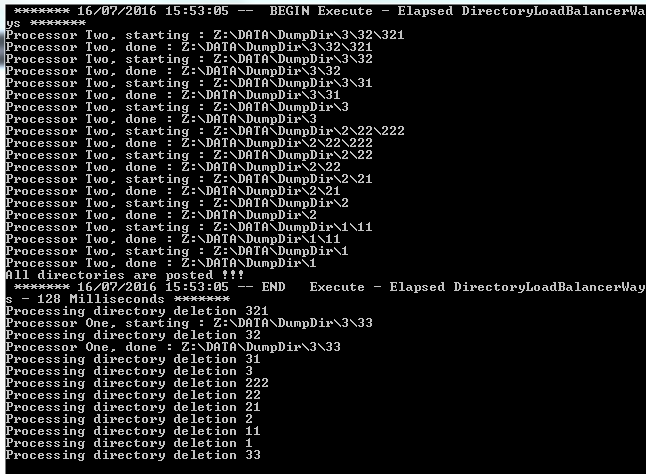
The folder 3 ( Z:\DATA\DumpDir\3 ) is empty but is not deleted , because runtime try to delete 3 before 33.
This is due to parallelism of directory processing. Even if we wait for all task to terminate before executing directory processing previous result may happen
So take care about parallelism.
VII. RUN PROCESSSTEP RECURSIVELY USING TPL DATAFLOW
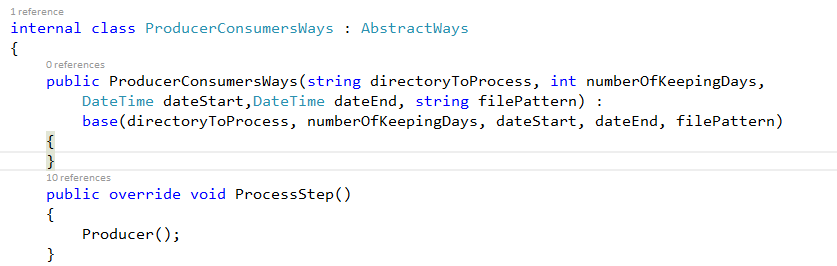
VIII. RUN PROCESSSTEP USING PRODUCER CONSUMER

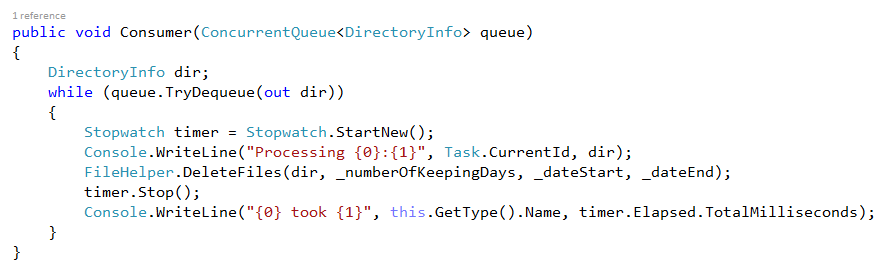
IX. RUN PROCESSSTEP USING ASYNCHROUNOUS PARALLEL PROCESSING

XI. OPTIMIZATION
before optimizing, lets analyse result first
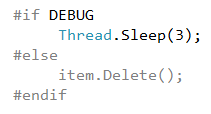
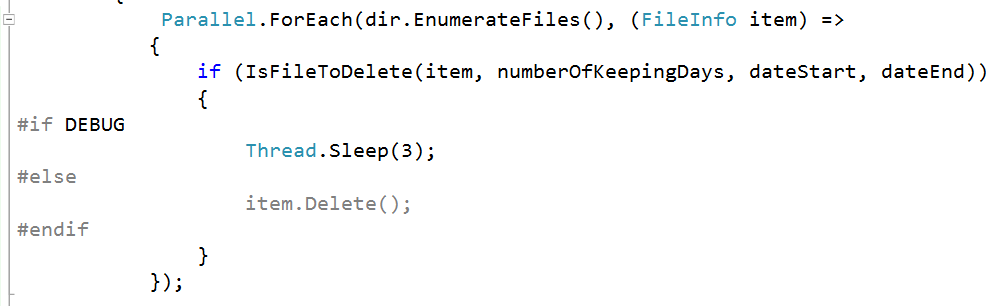
we need to run all concrete classes on the same file system, so we can use directives to simulate deleting files and directories process. We assume that our system need 3 milliseconds to delete a file, you can increase or decrease this value according to use case.
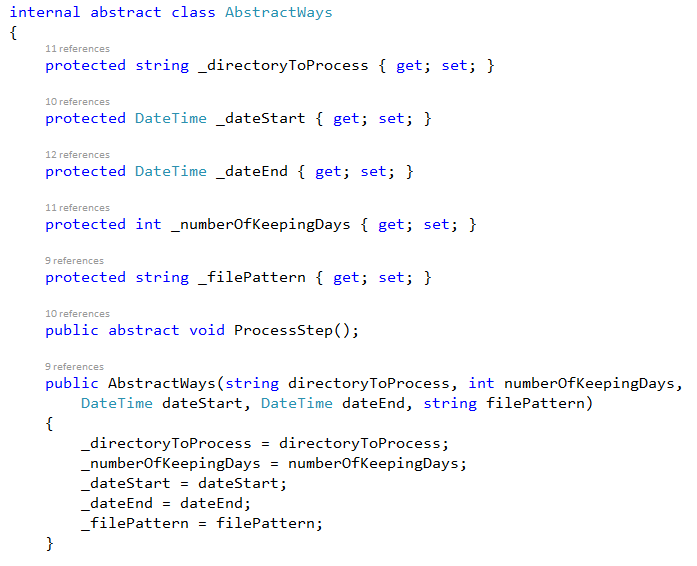
We used an abstract class to define the skeleton of the algorithm in an operation (ProcessStep), and lets subclasses redefine the step of the algorithm without changing the algorithm’s structure

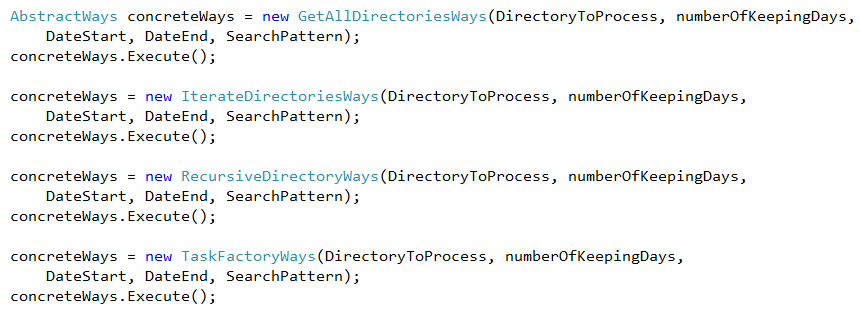
We instanciate concrete classes like this
private static void Main(string[] args)
{
var DirectoryToProcess = ConfigurationManager.AppSettings[“DirectoryToProcess”];if (!Directory.Exists(DirectoryToProcess))
{
throw (new Exception(“Le dossier à traiter est introuvable”));
}DateTime DateStart;
DateTime.TryParseExact(ConfigurationManager.AppSettings[“DateStart”],
“dd/MM/yyyy”,
CultureInfo.InvariantCulture,
DateTimeStyles.None,
out DateStart);if (DateStart == DateTime.MinValue)
{
throw (new Exception(“La date de début est incorrecte “));
}DateTime DateEnd;
DateTime.TryParseExact(ConfigurationManager.AppSettings[“DateEnd”],
“dd/MM/yyyy”,
CultureInfo.InvariantCulture,
DateTimeStyles.None,
out DateEnd);if (DateEnd == DateTime.MinValue)
{
throw (new Exception(“La date de fin est incorrecte “));
}
var SearchPattern = ConfigurationManager.AppSettings[“SearchPattern”];int numberOfKeepingDays;
int.TryParse(ConfigurationManager.AppSettings[“NumberOfKeepingDays”], out numberOfKeepingDays);AbstractWays concreteWays = new GetAllDirectoriesWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new IterateDirectoriesWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new RecursiveDirectoryWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new TaskFactoryWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new AsynchronousWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new AsynchronousParallelProcessFilesWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new ProducerConsumersWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new DirectoryLoadBalancerWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();concreteWays = new RecursiveDataflowWays(DirectoryToProcess, numberOfKeepingDays, DateStart, DateEnd, SearchPattern);
concreteWays.Execute();
Console.Read();
}
An execution of the code below may produce the following output
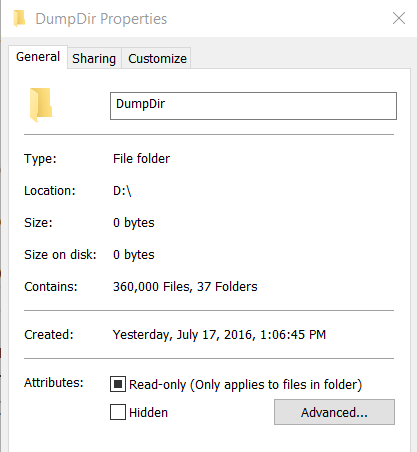
For our test, we have generated 360.000 files on 37 folders
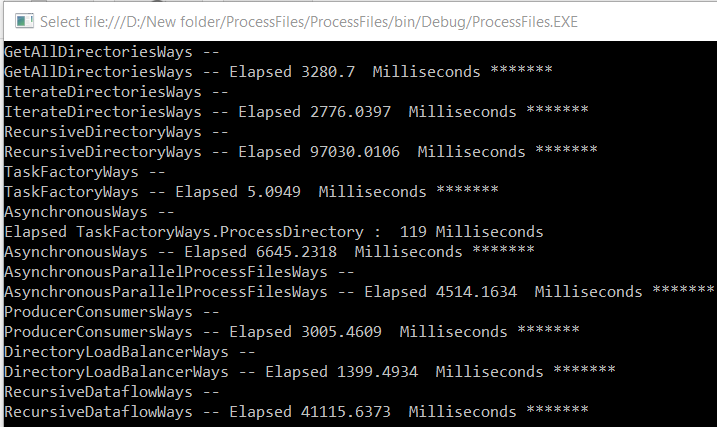
Directory.GetDirectories (or Directory.GetFiles) vs Directory.EnumerateDirectories (or Directory.EnumerateFiles)
When we use EnumerateDirectories(or EnumerateFiles) , we can start enumerating the collection before the whole collection is returned
But when we use GetDirectories (or GetFiles) , we must wait for the whole array to be returned before we can access the array.
Therefore, when we work with many files and directories, EnumerateFiles can be more efficient.
But in a broadcast system where files arrive continuously, it is better to first get all files to process ( by using GetDirectories or GetFiles ) so as to ignore the latest files ( in our case latest file will not be deleted).
Using EnumerateDirectories or EnumerateFiles latest files may be processed because when the system is currently processing an item, new items can be added on directories, so on collection
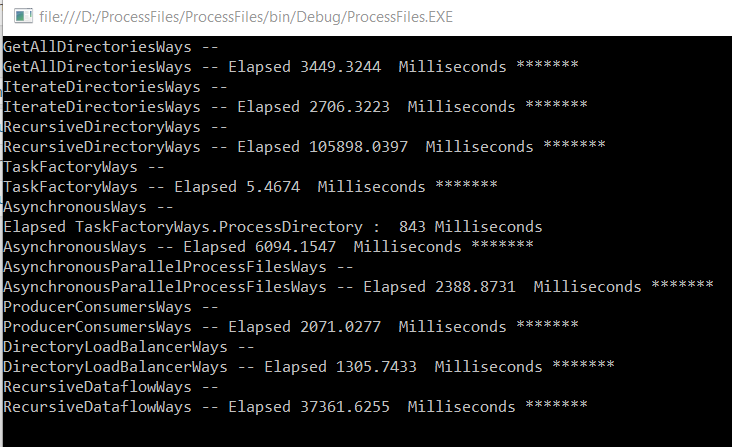
Using Parallelism
We cannot parallelize directory processing because the runtime may start deleting C:\DATA\DumpDir\2 before C:\DATA\DumpDir\2\21
In our case C:\DATA\DumpDir\2\21 will be deleted but not C:\DATA\DumpDir\2.
We can wait processing of C:\DATA\DumpDir\2 until C:\DATA\DumpDir\2\21 is processed but we do not know at this moment if C:\DATA\DumpDir\2\21 will be deleted or not ( not contains files or subdirectories)
So take care about parallelizm.
First, we need to mind if a function can be parallelized?
Consider the algorithm to calculate the Fibonacci numbers
(1, 1, 2, 3, 5, 8, 13, 21, etc.). The next number in the sequence is the sum of the previous two numbers.
Therefore, to calculate the next issue, we have already calculated the previous two. This algorithm is inherently
sequentially, so as much as we may try, it can not be parallelized.
So we can parallelize file processing because files have no connection between them
An execution of the code below may produce the following output
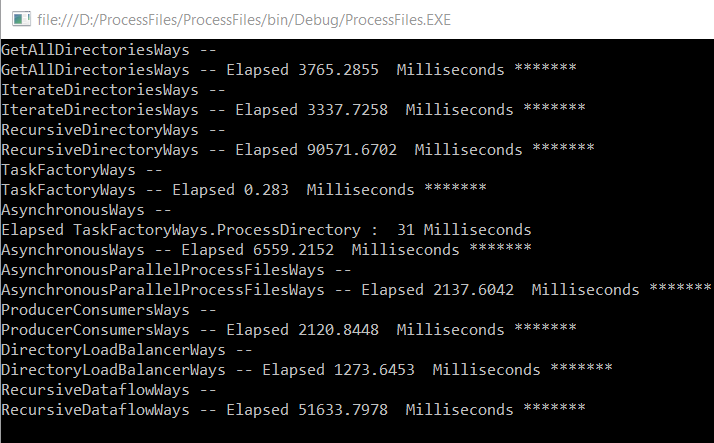
Using GetFiles instead of EnumerateFiles
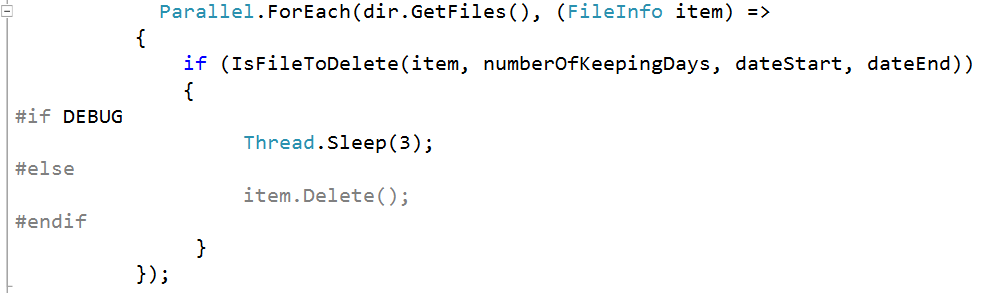
An execution of the code below may produce the following output
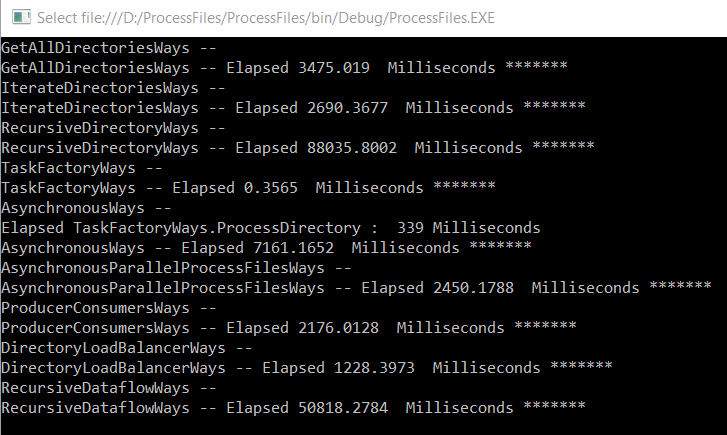
Using Task.Factory.StartNew
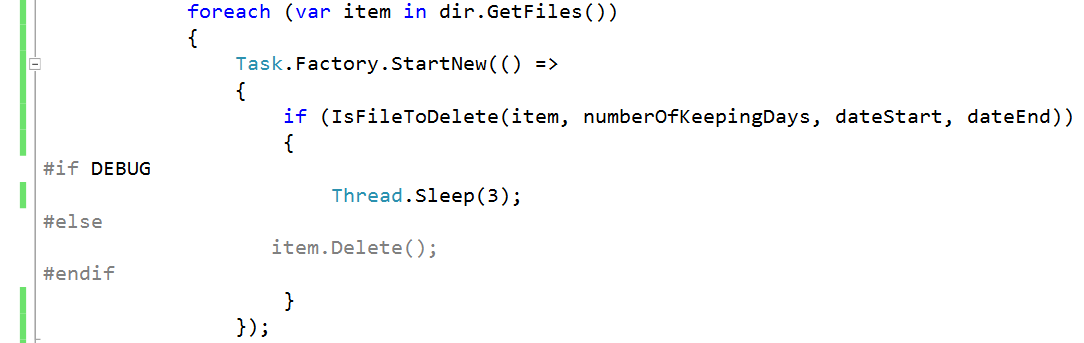
An execution of the code below may produce the following output
XII. RUN PROCESS AS A JOB USING QUARTZ.NET JOB SCHEDULLER
Please take a look at the following Using Spring.NET and Quartz.NET Job Scheduler
Source code will be available soon
Related Posts
 Asp.Net Core Web Api Integration testing using EntityFrameworkCore LocalDb and XUnit2
Asp.Net Core Web Api Integration testing using EntityFrameworkCore LocalDb and XUnit2- Asp.Net Core Web Api Integration testing using InMemory EntityFrameworkCore Sqlite and XUnit2
 Build 2016 : .NET Core
Build 2016 : .NET Core Using Spring.NET and Quartz.NET Job Scheduler
Using Spring.NET and Quartz.NET Job Scheduler Mastering Custum ASP.NET MemberShip Provider using ASP.NET MVC
Mastering Custum ASP.NET MemberShip Provider using ASP.NET MVC Building microservices through Event Driven Architecture part8: Implementing EventSourcing on Application
Building microservices through Event Driven Architecture part8: Implementing EventSourcing on Application